核心:微调主要教会 LLM "模式", 而非"知识".
理解这一点至关重要.微调调整的是模型的顶层参数, 使其能够识别和复制特定的文本模式, 而不是向模型灌输新的事实性知识.
什么时候应该考虑微调?
1. 输出特定格式或风格
- 需求场景: 需要模型严格按照某种格式输出, 例如生成特定结构的 JSON、XML, 或者模仿某种独特的写作风格(如莎士比亚戏剧腔调), 或者控制输出文本的长度火模式(例如, 总是输出单一句子的品牌口号, 输出固定词牌名格式的诗词等等).
2. 映射特定的输入到特定的输出
- 需求场景: 您希望模型能够稳定地将某一特定类型的输入信息, 转化为另一种特定类型的输出信息.比如格式转换器.
3. 专门化模型以执行狭窄、定义明确的任务
- 需求场景: 您需要一个在某个特定、垂直领域或任务上表现卓越的模型, 而不是一个"万金油"式的通用模型.比如医学模型.
4. 当提示工程
- 需求场景: 您已经投入了大量精力进行提示词设计和优化, 但模型输出的稳定性、格式一致性或风格符合度仍旧无法达到预期.
什么时候不应该(或者优先不考虑)微调?
1. 试图教授模型新的知识或事实
- 原因: 微调主要影响模型的表层行为模式, 并不能有效地让模型"记住"或"理解"新的事实性信息.模型的知识主要来源于其大规模的预训练阶段.
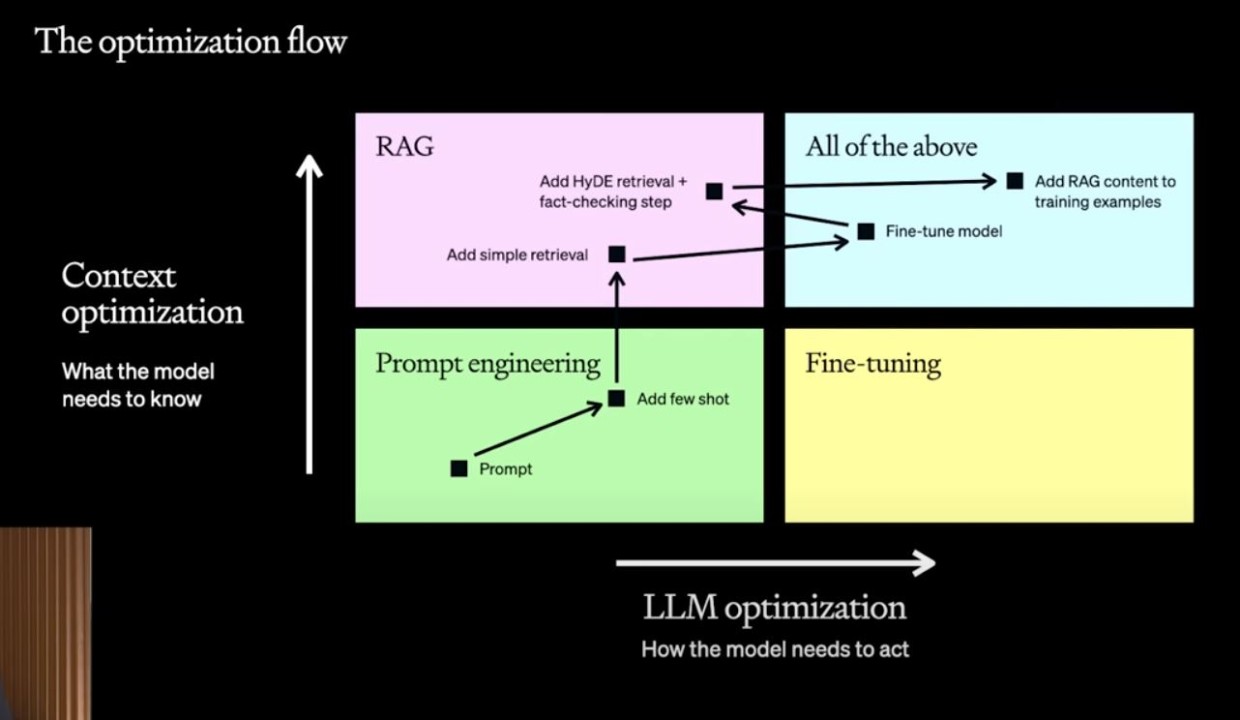
- 替代方案: 对于需要模型掌握并运用最新知识的场景, 应优先考虑**检索增强生成 ** 等技术.RAG 允许模型在生成文本时, 动态地从外部知识库(如数据库、文档集)中检索相关信息并融入到回答中.
- 例子:
- 试图通过微调让模型记住您公司最新的产品规格参数.
- 期望模型通过微调学习并回答关于最近发生的全球新闻事件的问题.
2. 期望模型获得复杂的推理能力
- 原因: 微调通常不会显著提升模型的基础逻辑推理、数学计算或复杂问题解决能力.这些核心能力更多地是在预训练阶段形成的.
- 例子: 期望通过微调使模型能够解决复杂的数学定理证明或进行多步骤的逻辑演绎.
3. 训练数据集质量低下或缺乏多样性
- 原因: 微调的效果高度依赖于训练数据的质量和多样性.如果您的数据集规模过小、包含大量错误、或者样本间的差异性不足(即所谓的"数据聚类", 所有样本都高度相似), 那么微调很可能无法达到预期效果, 甚至可能损害模型原有的性能.结果就是 "垃圾进, 垃圾出" .
- 例子: 使用少量高度同质化的邮件样本去微调一个通用邮件回复模型, 结果可能导致模型只会生成非常单一和刻板的回复.
4. 任务目标可以通过提示工程轻松实现
- 原因: 如果通过精心设计和优化的提示词, 模型已经能够很好地完成您的任务, 那么进行微调可能是一种不必要的资源投入(包括时间、计算资源和数据标注成本).
- 例子: 只需要模型进行简单的文本改写、总结或回答基于上下文的简单问题, 这些通常通过提示工程就能解决.
微调的最佳实践总结
成功的微调遵循以下关键原则:
- 明确目标:微调重在模式, 而非知识 清楚微调的强项是学习和复制文本的结构、风格和格式, 而不是记忆事实.
- 定义清晰的输入-输出映射 您的训练数据应该清晰地展示您期望模型如何从给定的输入转换到期望的输出.
- 拥抱数据多样性 训练样本应尽可能覆盖各种文体、风格、格式、长度和主题, 这能促使模型学习到更具泛化能力的模式.
- 包含对抗性/边缘案例 引入一些格式错误、内容异常或可能触发非预期行为的样本, 可以增强模型在真实场景中的鲁棒性.
- 警惕数据聚类 确保您的训练数据不是仅仅集中在某一非常狭窄的子集上, 除非您的目标就是创建一个针对该子集的超专用工具.广泛分布的数据能带来更灵活的生成能力.
- 专注专门化任务 一次微调解决一个定义明确的问题.微调旨在打造"专科医生", 而非"全科医生".
- 知识获取靠整合, 而非灌输 对于需要外部知识的任务, 应采用 RAG 等方法, 而不是试图通过微调将知识"塞进"模型.